

Facebook, uploaden van foto’s en taggen Facebook Pagina’s: Wat zijn de mogelijkheden?

Onlangs werd mij gevraagd wat de mogelijkheden zijn om personen en Pagina’s in Facebook foto’s en posts te taggen. Een kort onderzoekje, bracht me op de volgende conclusies:
Vraag: Onderzoek of het mogelijk is voor een Facebook gebruiker om:
- een foto te uploaden op de eigen wall
- die middels een mention dan wel tag automatisch ook op de Wall komt van de Facebook Pagina van je klant
- en ook zichtbaar is voor andere fans (die geen vriend zijn van de uploader) van die Facebook Pagina
Resultaten
- Een foto uploaden op de wall van een Facebook Pagina brengt deze foto NIET in de nieuwsfeed van je vrienden. Ongeacht privacy instellingen van deze foto (publiek of niet, foto komt niet op de nieuwsfeed van vrienden). Kans bestaat dat dit WEL gebeurt als vrienden ook fan zijn van deze Pagina.
- Een foto uploaden op de wall van een Facebook Pagina en deze vervolgens liken brengt deze foto NIET in de nieuwsfeed van je vrienden. Ongeacht privacy instellingen van deze foto (publiek of niet, foto komt niet op de nieuwsfeed van vrienden). Kans bestaat dat dit WEL gebeurt als vrienden ook fan zijn van deze Pagina.
- Een foto uploaden op de wall van een Facebook Pagina en deze vervolgens sharen brengt de foto WEL in de nieuwsfeed van je vrienden. Echter, als je vrienden op “like” klikken komen die toe aan de share en NIET de foto. Op de wall van de Facebook Pagina zie je er geen likes door ontstaan.
- Een Facebook Pagina in een foto “taggen” wil niet altijd goed werken met Facebook Pagina’s i.v.m. locaties, en is bovendien omslachtig.
- Inchecken op een locatie met foto brengt deze foto NIET perse in de nieuwsfeed van vrienden.
- Een foto uploaden op de eigen profiel wall en daarin een mention verwerken van de pagina (door gebruik van het “@” teken en de pagina aan te klikken waardoor deze wordt gehyperlinkt in de tekst), brengt de foto WEL op de nieuwsfeed van vrienden en (indien publiek gepost) WEL op de wall van de Facebook Pagina. Dit zou dus de ideale oplossing zijn, echter…. Op de mobiele Facebook applicatie of mobiele website m.facebook.com lijkt het NIET mogelijk een Pagina in een mention te verwerken. Op een computer of tabled op www.facebook.com werkt het WEL. Het is eveneens afhankelijk van de app.
Conclusie
Alleen mogelijkheid 6 biedt perspectieven, maar voelt wat omslachtig. Mensen kunnen namelijk niet gebruik maken van de Facebook App op hun telefoon, maar dienen in te loggen op Facebook in hun webbrowser, dan komen ze op de mobiele site, vervolgens dienen ze over te schakelen op desktop modus en dan in hun browser een foto te uploaden en daarin een mention verwerken van de Pagina.
loading...
loading...



Social media, privacy en social semantic web… Weten wat niet wordt gedeeld.

Als ontwikkelaar van social media software wordt me vrij vaak de volgende stelling voorgeschoteld: “Als ik mijn profiel op een sociale netwerksite afscherm, dan is mijn privacy toch gewaarborgd? Dan weet je toch niets van mij?” Een zeer onjuiste aanname als je begrijpt dat er een verschil is tussen “niets weten” en “niets kunnen weten”. De uitleg doet het vaak goed op borrels en lezingen, dus allicht ook op de Yocter Social Media Blog.
Sociale netwerken en privacy
Er zijn allerlei sociale netwerken die allen verschillend omgaan met privacy. Of het nu gaat om Facebook, Twitter, Hyves of welk sociaal netwerk dan ook, allen worden door privacy waakhonden geregeld van van alles en nog wat beticht. Deze waakhonden claimen ‘gevaarlijke lekken’ te hebben ‘ontdekt’, waar het echter (mijns inziens) in veel gevallen echter gaat om verkregen inzicht over hoe verbanden kunnen worden gelegd die op sociale netwerken eng en gevaarlijk lijken, terwijl ze in het normale leven al millennia worden toegepast en uitgebuit. Ik ga dan ook niet specifiek in op een sociaal netwerk of wie op welke manier profielen beschermt, maar wil graag aantonen hoe Yocter met slimme software en op legale wijze (!!) meer over een beschermd profiel te weten kan komen. Deels om u te behoeden maar uiteraard ook om u inzicht te geven hoe deze informatie relevant kan zijn voor het bedrijfsleven.
Wat is een beschermd profiel?
 Zelf heb ik een afgeschermd Facebook profiel. Als je niet bent ingelogd zie je helemaal niets, maar na een account te hebben aangemaakt en in te loggen zul je wanneer we geen vrienden zijn naast mijn naam en een profiel foto alsnog meer over mij te weten komen (als we even aannemen dat het analyseren van mijn profiel foto wel erg veel werk wordt om daar informatie uit te halen).
Zelf heb ik een afgeschermd Facebook profiel. Als je niet bent ingelogd zie je helemaal niets, maar na een account te hebben aangemaakt en in te loggen zul je wanneer we geen vrienden zijn naast mijn naam en een profiel foto alsnog meer over mij te weten komen (als we even aannemen dat het analyseren van mijn profiel foto wel erg veel werk wordt om daar informatie uit te halen).
Je ziet niet wie mijn vrienden zijn, hoe oud ik ben, of ik een relatie heb, of ik van lezen houd… niets van dat alles. Het enige wat je zeker kunt weten, is dat ik een account bij Facebook heb.
Social semantic datamining (1)
Maar zoals in de introductie aangekondigd, gaat het niet om wat je weet, maar wat je kunt weten. Ik zal aan de hand van mijn eigen Facebook profiel uitleggen hoe ik met social semantic datamining (zoals ik het zelf noem) veel meer informatie kan achterhalen.
Social Semantic Datamining: Het verzamelen van data en door het leggen van verbanden in het social media landschap een zelf lerende database aanleggen
Social semantic datamining betekent zoveel als: “Het verzamelen van data en door het leggen van verbanden in het social media landschap een zelf lerende database aanleggen”. Dit klinkt ingewikkelder dan het is. Open maar eens wat foto albums van een willekeurig persoon of ga door een stapel ontvangen kerstkaarten, en je weet binnen een paar minuten meer over iemand dan die persoon zelf kan (of wil) vertellen.
 Kortom, wat we nodig hebben om meer over mij te weten te komen is data. Veel data. Nu deel ik niet wie mijn vrienden zijn, maar dat wil niet zeggen dat mijn vrienden hetzelfde doen. Immers, mijn vrienden heb ik niet in de hand en die delen wel dat ik een vriend ben, zoals Mladen en Samù bijvoorbeeld. Kortom, als ik niet wil zeggen wie mijn vrienden zijn, dan kijk je gewoon bij naar mensen die zeggen dat ze vrienden met mij zijn.
Kortom, wat we nodig hebben om meer over mij te weten te komen is data. Veel data. Nu deel ik niet wie mijn vrienden zijn, maar dat wil niet zeggen dat mijn vrienden hetzelfde doen. Immers, mijn vrienden heb ik niet in de hand en die delen wel dat ik een vriend ben, zoals Mladen en Samù bijvoorbeeld. Kortom, als ik niet wil zeggen wie mijn vrienden zijn, dan kijk je gewoon bij naar mensen die zeggen dat ze vrienden met mij zijn.
Als we vervolgens ook de vrienden van die vrienden verzamelen en zo een paar tientallen of honderdtallen profielen bij elkaar hebben die wel informatie delen, kijken we naar andere informatie die wordt gedeeld. Zoals de gemiddelde leeftijd van deze groep, het percentage mensen dat een relatie heeft, wat voor soort relaties dat zijn (homo, hetero, verloofd, getrouwd…), hoe groot het gemiddelde aantal vrienden is, wat de politieke voorkeur is en in het geval van Facebook, waar deze groep mensen fan van is. Met andere woorden, door een enorme hoeveelheid data te verzamelen van wat mijn vrienden en de vrienden van mijn vrienden delen, beginnen we een aardig beeld te krijgen van wie ik zelf ben.
Vertel mij wie uw vrienden zijn, en ik vertel u wie gij zijt.
Als we via bovenstaande methode van een paar honderd mensen gegevens kunnen verzamelen, kunnen we al een aardig beeld vormen van wie ik ben. Immers:
- De gemiddelde leeftijd van deze groep ligt rond de 30
- Het grootste deel van deze groep is man
- Er zitten meer hetero mannen bij dan homoseksuele mannen
- Er zitten niet bijzonder veel mensen tussen die hebben aangegeven fan te zijn van een voetbalclub
- De meeste van deze mensen wonen in Nederland
Kortom, door simpelweg de informatie te gebruiken van mensen om mij heen, kunnen we zeer aannemelijke conclusies maken (verbanden trekken dus). Met andere woorden: Zo afgeschermd als mijn profiel lijkt, is het helemaal niet.
Social semantic datamining (2)
Als je van Pulp Fiction houdt, ben je geïnteresseerd in liberale boeken in het Nederlands of Engels en eet je daar graag aardbeien bij.
Maar we kunnen nog veel verder komen als we de verzamelde informatie vergelijken met informatie verzameld uit andere zoektochten. Stel andere datamining resultaten hebben ons het volgende geleerd (dit is puur als voorbeeld, lees dit dus niet als waarheden):
- 80% van de mensen die van de film Pulp Fiction houdt, houdt ook van aardbeien.
- 70% van de mensen die in Nederland wonen, spreken Engels
- 90% van de mensen die van aardbeien houden, stemmen liberaal
- 80% van de Nederlandser die Engels spreken EN van aardbeien houden EN fan zijn van Pulp Fiction, lezen veel boeken
 Met deze gegevens is ineens veel meer aannemelijk te maken. Is iemand fan van Pulp Fiction? Dan zouden we in combinatie met social semantic datamining (1) precies kunnen weten welke boek-advertentie bol.com deze persoon zou moeten voorhouden.
Met deze gegevens is ineens veel meer aannemelijk te maken. Is iemand fan van Pulp Fiction? Dan zouden we in combinatie met social semantic datamining (1) precies kunnen weten welke boek-advertentie bol.com deze persoon zou moeten voorhouden.
Gevaarlijk of nuttig?
Social semantic datamining is een zeer interessante tak van sport en niet voor niets een steeds belangrijker onderdeel in de binnenkort te lanceren social media management tool SocialDrums (ok, schaamteloze reclame. Excuses.) Of het gevaarlijk is en/of nuttig laat ik graag aan jullie over. Reacties zijn uiterst welkom en ik beloof geen social semantic datamining op je los te laten ![]()
UPDATE
Na reactie en op verzoek van Sander van den Hoven, een aanvullend voorbeeld om de toepassing van social semantic dataminig te illustreren:
(1). Stel , een nieuw frisdrank merk heeft een Facebook Fanpage waar 200 leden fan zijn. Met social semantic datamining zou het bedrijf kunnen bepalen op welk festival ze met een grote promotie-stand willen gaan staan deze zomer. Door te analyseren welke festival de eigen fanbase en de vrienden van de fanbase (gaan) bezoeken.
(2). Je kunt nog verder gaan door vervolgens de groep die je middels de datamining bijeen hebt gebracht te blijven analyseren. Zodra iemand aangeeft daadwerkelijk naar het festival te gaan (bijvoorbeeld door een status update of door fan te worden van bv Lowlands 2011) sla je zijn naam + profielfoto op maar ook die van zijn vrienden. Je analyseert vervolgens deze groep apart waardoor je weet wat deze groep bindt (bijvoorbeeld wat zij het meest gemeen hebben, zoals allemaal fan van Ajax). Dit alles is volledig te automatiseren waardoor je eenmaal op het festival een groot scherm hebt waar je de foto van deze persoon en zijn vrienden in combinatie met bijvoorbeeld het logo van Ajax erbij en de tekst: He Sander, kom je met je vrienden even een drankje doen?”
(3). Als hij daadwerkelijk met zijn vrienden komt, maak je een foto van de groep en vraagt hem (ter plekke) lid te worden van de Fanpage. Na het festival vraag je deze persoon de mensen in de foto te ‘taggen’. De volgende ronde semantic datamining is door te zoeken naar combinaties waar exact deze groep ook samenkomt. Bijvoorbeeld andere foto’s van vakanties waar exact deze groep op staat zoals een vakantie op Ibiza. Dit herhaal je een paar honderd keer en je hebt een zeer mooie targeted groep om samen met een bekende tour operator gezamenlijk een aanbieding te doen aan deze groep.
(Geschreven door Godfried van Loo, Creative Director & Founder Yocter b.v.)
loading...
loading...
Rockmelt, De social media web browser.

Begin deze maand (november 2010) werd een nieuwe web browser gelanceerd met de naam Rockmelt. Twee jaar geleden lanceerde Google een nieuwe browser genaamd Chrome. Toen al was de concurrentie tussen web browsers moordend dus is de grote vraag: Is er ruimte voor nog een browser? Dan moet dit wel een heel bijzondere browser zijn. Rockmelt noemt zichzelf een ‘sociale web browser’ en na Rockmelt even gebruikt te hebben is het ‘sociale’ inderdaad zeer duidelijk aanwezig.Maar of het genoeg is…
Rockmelt: De Facebook browser

Screenshot van Rockmelt
Op internet wordt Rockmelt ook wel de Facebook browser genoemd. De meeste sociale onderdelen richten zich namelijk vooral op Facebook, al is ook Twitter prima geintegreerd. Na het installeren van Rockmelt wordt je dan ook gevraagd je accounts te koppelen zodat deze mooi kunnen worden opgenomen in je ‘Rockmelt experience’. Van het “integreren” is in eerste instantie niet meer te zien dan het verschijnen van een balk met Facebook contacten links en een balk met Twitter knopjes rechts. Verder lijkt Rockmelt vooral op Google Chrome. Niet verwonderlijk, want Rockmelt is gebouwd op de open source variant van Chrome; Chromium.
Delen, zo veel en vaak je kunt

Deel webpagina eenvoudig
Een ander duidelijk aanwezig verschil met de ‘normale’ versie van Chrome, is een “Share” button rechts van de adres balk. Zo kan je de website die je bekijkt direct delen op Facebook of Twitter. Wat bijzonder praktisch is, is dat (zoals gezegd) je meerdere accounts kunt koppelen. Zo heb ik nu in Rockmelt mijn eigen persoonlijke Twitter account gekoppeld (@gvanloo) maar ook die van Yocter (@yocter). Aan de rechter zijde kan ik bovendien een update plaatsen en snel schakelen tussen accounts. Hoewel uiterst simpel, komt hier dus een gelijkenis met HootSuite of SocialDrums om de hoek kijken.
Chrome op social steroids; is dat genoeg?

Marc Andreessen
Rockmelt geniet vooral veel publiciteit door een van de investeerders: Marc Andreessen, oprichter van de legendarische browser Netscape. Of het sociale aan Rockmelt genoeg is om de strijd aan te gaan met de andere browsers is echter maar de vraag. Rockmelt lijkt in eerste instantie vooral een Chrome versie met ingebouwde sociale plugins. Veel van deze foefjes zijn echter ook al tijden los te realiseren met plugins in andere browsers. Dat Rockmelt een alles-in-een oplossing biedt, lijkt mij niet de reden voor een massale overstap.
Alleen op uitnodiging? Win een invite!
Rockmelt is vooralsnog alleen beschikbaar op uitnodiging (invitation-only). Wil je ook Rockmelt eens proberen? Tweet dan dit artikel en volg @yocter op Twitter! Wij verloten namelijk 2 invites onder onze volgers!
Invites zijn inmiddels vergeven.
loading...
loading...
Blekko.com, de nieuwe sociale zoekmachine. Hoe werkt Blekko?

Zoekmachines komen en gaan. Voor het Google tijdperk hadden we Altavista en de toen oh zo bekende namen als vinden.nl, ilse.nl en zoeken.nl. Wie niet wist hoe hij de hardnekkige en na elke update terugkerende Microsoft startpagina kon wijzigen in Internet Explorer, zat echter vast aan MSN Search. Maar nu Google de strijd jaar in jaar uit gewonnen lijkt te hebben, wordt het op allerlei fronten aangevallen. Zo probeert Microsoft het met Bing via een deal met Facebook en “doet het nu ook Yahoo“. Maar ook compleet nieuwe zoekmachines komen zo nu en dan voorbij. Zo is dat deze maand Blekko.
Zoeken in Google
 Zoeken in Google is bewust extreem eenvoudig. Je gaat naar Google, ziet een zoekveld en typt daar hetgeen in waarnaar je zoekt. Google analyseert vervolgens je woorden en geeft je zoekresultaten terug. Hoewel je vaak genoeg ziet dat Google meer dan 2 miljoen resultaten voor je heeft, moge het duidelijk zijn dat men veelal niet verder kijkt dan de resultaten op de eerste pagina. Hieruit kunnen we dan ook concluderen dat we Google eerder als een orakel zien dan een objectieve derden. Zoeken op ‘global warming’ in Google geeft me allerlei bronnen, maar het is vrij moeilijk te achterhalen wie nu wat zegt of wat het laatste nieuws is. Als ik geen standpunt heb met betrekking tot global warming, zal ik dan maar mijn standpunt moeten vormen aan de hand van de eerste 10 resultaten die Google mij geeft? Een vrij gevaarlijke vorm van objectiviteit, maar dagelijks doet de meerderheid van zoekend internet niet anders.
Zoeken in Google is bewust extreem eenvoudig. Je gaat naar Google, ziet een zoekveld en typt daar hetgeen in waarnaar je zoekt. Google analyseert vervolgens je woorden en geeft je zoekresultaten terug. Hoewel je vaak genoeg ziet dat Google meer dan 2 miljoen resultaten voor je heeft, moge het duidelijk zijn dat men veelal niet verder kijkt dan de resultaten op de eerste pagina. Hieruit kunnen we dan ook concluderen dat we Google eerder als een orakel zien dan een objectieve derden. Zoeken op ‘global warming’ in Google geeft me allerlei bronnen, maar het is vrij moeilijk te achterhalen wie nu wat zegt of wat het laatste nieuws is. Als ik geen standpunt heb met betrekking tot global warming, zal ik dan maar mijn standpunt moeten vormen aan de hand van de eerste 10 resultaten die Google mij geeft? Een vrij gevaarlijke vorm van objectiviteit, maar dagelijks doet de meerderheid van zoekend internet niet anders.
Blekko introduceert ‘slashtags’
global warming /conservative
global warming /conservative /date
tech /apple
apple /tech
apple /tech /people /date
Blekko is in beginsel “gewoon weer een zoekmachine”. Je gaat naar blekko.com en typt je zoektermen in, net zoals je zou doen bij Google. Wat er anders is aan Blekko, en duidelijk wordt in hun slogan “Slash the web!”, is de mogelijkheid slashtags te gebruiken. Slashtags kan je zien als filters. Als je je spamfilter in je emailprogramma aanzet, zal deze proberen de spammails uit je emails te filteren. Bij Blekko kan je filters toepassen op je zoekresultaten door er een ‘slashtag’ achter te zetten. Dat doe je door het “/” teken te gebruiken en een woord erachter te zetten. Zo kan je bijvoorbeeld op opinies filteren. Je kunt, zoals in bovenstaand voorbeeld, bij Blekko zoeken op ‘global warming’ en krijgt net als bij Google resultaten m.b.t. global warming terug. Echter, als je de slashtag ‘/green’ erachter zet krijg je alleen resultaten te zien van websites die een ‘green friendly’ standpunt innemen. Wil je liever weten wat de laatste berichtgeving is? Dan gebruik je de slashtag ‘/date’ en de zoekresultaten worden gesorteerd op tijd met het meest recente resultaat bovenaan. En zo zijn er tal van andere slashtags die je kunt gebruiken waarmee je zelf invloed kunt uitoefenen op je zoekresultaten en uiteraard kan je ze ook combineren. Bedenk maar eens wat voor zoekresultaten je kunt verwachten, en hoe die verschillen met die bij Google, met de zoekopdrachten in het veld hierboven.
Zelf slashtags maken en delen
Blekko heeft allerlei slashtags al zelf aangemaakt, maar je kunt ook zelf slashtags maken en zo nog meer invloed uitoefenen op je eigen resultaten. Daarnaast kan je gebruik maken van het ‘slashtagwerk’ van anderen door hun slashtags te gebruiken. Een mogelijkheid die doet denken aan StumbleUpon of Digg. Blekko wordt daarmee een sociale zoekmachine maar is hierdoor uiteraard ook in staat het menselijke filterwerk te gebruiken om de eigen resultaten te verbeteren. Wat mensen nog altijd beter kunnen dan de bots van Google, is spam onderscheiden van niet-spam. Het is dan ook niet verbazingwekkend dat Blekko een ‘spam’ knop bij de zoekresultaten heeft staan. Een optie die we al internet-eeuwen kennen van fora en sociale netwerken, maar bij Blekko kan je met deze spam knop je eigen internet zuiveren. Als je een website als spam markeert, zal Blekko je nooit meer een resultaat van deze website laten zien.
Blekko… Een goed en origineel begin
We hebben veel zoekmachines zien komen en gaan, allen met een niche of “bijzondere aanpak” zoals (één van de vele) ‘groene’ Forstle, audio zoekmachine Podscope, forum zoekmachine Zhift, of privacy vriendelijke Cuil. De laatste was nog in 2008 met veel bombarie aangekondigd, maar moest ruim een maand geleden (september 2010) door misgelopen overname offline worden gehaald. Of Blekko het wel gaat halen is de vraag, maar hun aanpak is absoluut opmerkelijk en veelbelovend te noemen. Zou Google hier wakker om liggen? Ook Google kent al tijden allerlei filter mogelijkheden al zijn die minder duidelijk dan de slashtags van Blekko. Zo kan je bij Google resultaten van één website krijgen door er “site:” en het domein achter te zetten (bijvoorbeeld site:yocter.nl) en een “-” teken gebruiken. Zo krijg je met “remmen -toyota” resultaten over remmen zonder dat Toyota genoemd wordt.
Wat er ook van Blekko gaat worden, het is in ieder geval duidelijk dat net als Google, Bing, Yahoo of Vinden.nl ook Blekko begrijpt wie er bovenaan dient te komen met een zoektocht op “social media voor bedrijven” ![]()
blekko: how to slash the web from blekko on Vimeo.
loading...
loading...
Het semantisch web in begrijpelijke taal

Het semantisch web… Wat is dat nu weer? Je hoort en leest er steeds meer over. Internet bedrijven, wetenschappers, overheden… Iedereen lijkt er druk mee maar wat is het semantic web in begrijpelijke taal? Waar komt het vandaan en wanneer “is het er dan”?
Semantisch wil zoveel zeggen als “de betekenis lerend”. Het semantisch web zou je grofweg kunnen definiëren als een web van verbanden. Verbanden gelegd tussen informatie op het internet, waardoor nieuwe inzichten kunnen ontstaan. Neem de volgende vier zinnen:
Voorbeeld: Het belang van verbanden leggen
 Tony Hayward is de CEO van BP
Tony Hayward is de CEO van BP- De CEO van BP zit op een zeilboot in de Golf van Mexico
- Er vaart slechts één boot in de Golf van Mexico
- Er is een zeilboot omgeslagen in de Golf van Mexico

Elk van deze vier zinnen is op zichzelf niet bijzonder spannend maar als we deze vier zinnen achter elkaar lezen, is te concluderen dat de CEO van BP (nog erger) in de problemen zit. Nu staan de vier zinnen handig genoeg toevallig achter elkaar in één blogpost, maar wat nu als elk van deze 4 nieuwsitems op totaal verschillende websites hadden gestaan?
Mens versus software
In bovenstaande voorbeeld is het voor een mens eenvoudig verbanden te leggen en tot bovenstaande conclusie te komen. Voor een computer is dit echter niet zo eenvoudig en al helemaal niet als deze vier zinnen los van elkaar op verschillende plekken hadden gestaan. Hoe had een computer of internet spider dit verband kunnen leggen? Dat is vrijwel onmogelijk. Tenzij we speciaal voor een computer wat extra informatie zouden kunnen geven. Informatie die de informatie beschrijft. Speciaal voor computers.
Beschrijvende informatie in onzichtbare broncode: snippets en microformats
 De broncode van een webpagina bevat naast de getoonde informatie ook informatie over opmaak zoals lettertype, afbeeldingen, animaties, links en menu’s. Met links worden websites aan elkaar gekoppeld en vindbaar maar voor het Semantic Web zijn een paar links niet genoeg. Het is slechts een verwijzing. Voor computers/software/spiders is het belangrijk te begrijpen wat de relatie van de verwijzing is tot het artikel. En daarvoor zijn zogenoemde ‘rich snippets’ en microformats bedacht. Het zijn stukjes broncode die informatie omschrijven of juist verrijken door de informatie aan andere gerelateerde informatie te koppelen.
De broncode van een webpagina bevat naast de getoonde informatie ook informatie over opmaak zoals lettertype, afbeeldingen, animaties, links en menu’s. Met links worden websites aan elkaar gekoppeld en vindbaar maar voor het Semantic Web zijn een paar links niet genoeg. Het is slechts een verwijzing. Voor computers/software/spiders is het belangrijk te begrijpen wat de relatie van de verwijzing is tot het artikel. En daarvoor zijn zogenoemde ‘rich snippets’ en microformats bedacht. Het zijn stukjes broncode die informatie omschrijven of juist verrijken door de informatie aan andere gerelateerde informatie te koppelen.
Voorbeeld: Wat gebeurt er in de familie van X?
 Als je je familie aan iemand voorstelt, vermeld je daarbij ook vaak de relatie tot jou. “Dit is mijn moeder, mijn broer, neef, kleinkind, etc”. Als je met je hele familie zou afspreken dat iedereen op zijn/haar eigen blog slechts één link plaatst naar een ander familielid en de link omschrijft met microformats, dan is het voor een computer (dan wel spider) mogelijk om te bepalen “wie jouw hele familie is”. Als een verre achterneef een kindje krijgt, is het dus geen kunst meer vast te stellen dat “er in jouw familie een kindje is geboren”. En dat allemaal doordat je één link naar een ander familielid hebt geplaatst.
Als je je familie aan iemand voorstelt, vermeld je daarbij ook vaak de relatie tot jou. “Dit is mijn moeder, mijn broer, neef, kleinkind, etc”. Als je met je hele familie zou afspreken dat iedereen op zijn/haar eigen blog slechts één link plaatst naar een ander familielid en de link omschrijft met microformats, dan is het voor een computer (dan wel spider) mogelijk om te bepalen “wie jouw hele familie is”. Als een verre achterneef een kindje krijgt, is het dus geen kunst meer vast te stellen dat “er in jouw familie een kindje is geboren”. En dat allemaal doordat je één link naar een ander familielid hebt geplaatst.
Semantisch web is er al
 Het semantisch web klinkt als een belofte. Als “iets in de toekomst” wat we hopelijk nog gaan meemaken. Maar het semantisch web is er al, het moet alleen nog groeien. Hoe meer webbouwers gebruik zullen maken van snippets en microformats en niet alleen links plaatsen, maar ook ook verbanden verklaren, hoe groter het semantisch web wordt. Grote maar ook kleine internet partijen doen al mee. Uiteraard maken bedrijven als Google, Yahoo en Facebook steeds meer gebruik van het semantic web maar ook andere partijen ontdekken het belang ervan. Berichten als “Health sites use semantic technologies to provide better results” zullen we dan ook steeds vaker gaan tegenkomen. Uitgever Bohn Stafleu van Loghum, onderdeel van Springer Media, heeft bijvoorbeeld bij de ontwikkeling van zorgkaartnederland.nl ook al microformats toegepast liet Product Manager Jos Groenendaal mij weten. Onzichtbare stukjes broncode als je de website bezoekt, maar voor zoekmachines als Google (die de verbanden ook al in zoekresultaten laat zien) bijzonder gewaardeerd.
Het semantisch web klinkt als een belofte. Als “iets in de toekomst” wat we hopelijk nog gaan meemaken. Maar het semantisch web is er al, het moet alleen nog groeien. Hoe meer webbouwers gebruik zullen maken van snippets en microformats en niet alleen links plaatsen, maar ook ook verbanden verklaren, hoe groter het semantisch web wordt. Grote maar ook kleine internet partijen doen al mee. Uiteraard maken bedrijven als Google, Yahoo en Facebook steeds meer gebruik van het semantic web maar ook andere partijen ontdekken het belang ervan. Berichten als “Health sites use semantic technologies to provide better results” zullen we dan ook steeds vaker gaan tegenkomen. Uitgever Bohn Stafleu van Loghum, onderdeel van Springer Media, heeft bijvoorbeeld bij de ontwikkeling van zorgkaartnederland.nl ook al microformats toegepast liet Product Manager Jos Groenendaal mij weten. Onzichtbare stukjes broncode als je de website bezoekt, maar voor zoekmachines als Google (die de verbanden ook al in zoekresultaten laat zien) bijzonder gewaardeerd.
Scoutle.com
 “Semantisch” wil natuurlijk niet altijd zeggen dat websites “gebruik maken van rich snippets en microformats volgens bepaalde afspraken”. Het in 2008 gelanceerde semantisch bloggersnetwerk Scoutle.com (ontwikkeld door ondergetekende) legt zelf verbanden en leert middels algoritmes de blogosfeer kennen, maar dan geautomatiseerd en zonder gebruik te maken van microformats of snippets. Scoutle leert juist door te kijken naar zowel bloggers als bezoekers van blogs en berekent daarbij voorkeuren en verbanden die worden gelegd.
“Semantisch” wil natuurlijk niet altijd zeggen dat websites “gebruik maken van rich snippets en microformats volgens bepaalde afspraken”. Het in 2008 gelanceerde semantisch bloggersnetwerk Scoutle.com (ontwikkeld door ondergetekende) legt zelf verbanden en leert middels algoritmes de blogosfeer kennen, maar dan geautomatiseerd en zonder gebruik te maken van microformats of snippets. Scoutle leert juist door te kijken naar zowel bloggers als bezoekers van blogs en berekent daarbij voorkeuren en verbanden die worden gelegd.
Semantic Ready: belang van meedoen aan het semantisch web
 Het moge duidelijk zijn dat het belang om je blog of website “Semantic Ready” te maken groeit want je wilt natuurlijk dat ook jouw website gaat opvallen en meedoet als computers verbanden gaan leggen. Terugdenken aan het voorbeeld van de familie… Wat als een familielid niet in het link-kringetje voorkomt? Dan zou die door de computer simpelweg worden uitgesloten. Het is dus voor elke website van belang ook in te gaan zetten op het semantic web. Want deze intelligente boot wil je niet missen.
Het moge duidelijk zijn dat het belang om je blog of website “Semantic Ready” te maken groeit want je wilt natuurlijk dat ook jouw website gaat opvallen en meedoet als computers verbanden gaan leggen. Terugdenken aan het voorbeeld van de familie… Wat als een familielid niet in het link-kringetje voorkomt? Dan zou die door de computer simpelweg worden uitgesloten. Het is dus voor elke website van belang ook in te gaan zetten op het semantic web. Want deze intelligente boot wil je niet missen.
(Geschreven door Godfried van Loo, Creative Director en Founder van Yocter b.v.)
loading...
loading...
Maakt social media Google Search en SEO achterhaald? Websitebouwers opgelet.

Een vakantie plan je natuurlijk ruim van tevoren en uiteraard via Internet. Je laat Google je vertellen waar je heen gaat, slaapt, welke bezienswaardigheden je gaat bezichtigen en misschien zelfs welke souvenirs je mee terug neemt. De zoektocht naar en vindbaarheid van informatie op internet wordt dan ook steeds belangrijker. Wordt het werkwoord ‘googelen’, net als ‘kaartlezen’, een ouderwets werkwoord? Duidelijk is dat er meer zaken zijn waar webbouwers naast SEO op moeten letten.
Gevonden worden in zoekmachines
Om informatie te vinden op internet, kan je een zoekmachine gebruiken. Je typt een paar termen in en er verschijnen resultaten. De volgorde van die resultaten (wat staat er op plek 1?) is van cruciaal belang. Zowel voor de persoon die zoekt, als de websites die graag gevonden worden op die combinatie zoektermen. Kapitalen gaan om in het zogenaamde “Search Engine Optimization” (SEO); zorgen dat een website zo hoog mogelijk scoort in zoekmachines en vooral, in Google.
Bepalen van de volgorde
 Voor het bepalen van de volgorde spelen veel factoren mee. Oude zoekmachines als Altavista of Ilse, lieten de volgorde bepalen door de ‘hoogste bieder’. De oprichters van Google vonden echter dat alleen de gevonden website daarbij is gebaat, niet de zoeker. Google kijkt naar de ‘inkomende links’ van een website; het aantal links dat naar een website verwijst. Immers, als heel veel andere websites een link hebben geplaatst naar de website van Yocter, dan is deze website vast waardevol en dus moet deze hoog terechtkomen in de resultaten wanneer mensen bijvoorbeeld zoeken op ‘social media voor bedrijven‘. Inmiddels zijn ook andere zoekmachines overgegaan op deze methode, zoals Bing van Microsoft.
Voor het bepalen van de volgorde spelen veel factoren mee. Oude zoekmachines als Altavista of Ilse, lieten de volgorde bepalen door de ‘hoogste bieder’. De oprichters van Google vonden echter dat alleen de gevonden website daarbij is gebaat, niet de zoeker. Google kijkt naar de ‘inkomende links’ van een website; het aantal links dat naar een website verwijst. Immers, als heel veel andere websites een link hebben geplaatst naar de website van Yocter, dan is deze website vast waardevol en dus moet deze hoog terechtkomen in de resultaten wanneer mensen bijvoorbeeld zoeken op ‘social media voor bedrijven‘. Inmiddels zijn ook andere zoekmachines overgegaan op deze methode, zoals Bing van Microsoft.
Is dit alles?
Google Search heeft niet stilgezeten en kijkt inmiddels naar veel meer dan links alleen, al is het basisprincipe (aantal inkomende links) gelijkgebleven. Maar social media maakt het mogelijk om op andere manieren aan je informatie te komen. Biedt Google nu een passend antwoord bij zoeken op ‘leuk restaurantje utrecht“? Waarschijnlijk niet, en dat komt vooral omdat iedereen zijn eigen idee heeft van wat ‘leuk’ is. Maar hoe kan Google nou weten wat ‘leuk’ is voor jou?
(EDIT:) Google kan je in zoekresultaten ook naar kaartjes sturen waar andere beoordelingen geven over restaurantjes of naar websites als iens.nl die eveneens veel aan SEO doen. Toch zou je tussen al die informatie misschien liever gewoon aan je vrienden vragen… Wat is een leuk restaurantje on Utrecht?
Zoeken met informatie die je niet opgeeft
![]() Google leert steeds meer en zal ook social media gaan gebruiken om zoekresultaten te verfijnen. Het duidelijkste voorbeeld is dat Google zo snel mogelijk social media wil indexeren om ernaar te kunnen verwijzen. Maar sociale netwerken hebben natuurlijk de meeste kennis van de social media die jij en je vrienden daar achterlaten. Immers, daarin geef je aan van welke muziek je houdt, wat voor werk je doet, waar je uitgaat, wat je lekker vindt, wie je vrienden zijn… En dat laatste is misschien nog wel het meest belangrijk. Want je vrienden, geven dit ook aan. Met al die informatie is ineens wel op te maken wat je ‘leuk’ vindt. Als 80% van je vrienden van motorrijden, tatoeages en bier houdt, zegt dat ook iets over jou. Het Nederlandse Rijschool Network, van Rory Ligthart, adviseert bijvoorbeeld via Hyves welke rijschool voor jou het meest interessant is. Dit op basis van waar je vrienden rijlessen hebben gehad en hoe ze dit vonden. Hiermee wordt “googelen” dan ook helemaal overgeslagen.
Google leert steeds meer en zal ook social media gaan gebruiken om zoekresultaten te verfijnen. Het duidelijkste voorbeeld is dat Google zo snel mogelijk social media wil indexeren om ernaar te kunnen verwijzen. Maar sociale netwerken hebben natuurlijk de meeste kennis van de social media die jij en je vrienden daar achterlaten. Immers, daarin geef je aan van welke muziek je houdt, wat voor werk je doet, waar je uitgaat, wat je lekker vindt, wie je vrienden zijn… En dat laatste is misschien nog wel het meest belangrijk. Want je vrienden, geven dit ook aan. Met al die informatie is ineens wel op te maken wat je ‘leuk’ vindt. Als 80% van je vrienden van motorrijden, tatoeages en bier houdt, zegt dat ook iets over jou. Het Nederlandse Rijschool Network, van Rory Ligthart, adviseert bijvoorbeeld via Hyves welke rijschool voor jou het meest interessant is. Dit op basis van waar je vrienden rijlessen hebben gehad en hoe ze dit vonden. Hiermee wordt “googelen” dan ook helemaal overgeslagen.
Ook voor het voorbeeld van het restaurantje gaat dit op, want mogelijk hebben je vrienden (of hun vrienden) ook wel eens ergens in Utrecht gegeten en op sociale netwerken aangegeven welke restaurantjes zij leuk vonden. Daarmee is ineens een stuk duidelijker wat jij bedoelt met ‘leuk restaurantje utrecht’. Iets wat Google je niet had kunnen vertellen.
Belang van Link en belang van Like
 Facebook opent nu de aanval op Google met een nieuwe manier van zoeken en gevonden worden. Met “Like” buttons kunnen mensen aangeven welke website of webpagina ze “leuk” vinden. Hiermee tippen ze enerzijds hun vrienden, zoals StumbleUpon dit ook doet, maar wordt deze informatie ook gebruikt om zoekresultaten in Facebook te rangschikken. Websites die door veel van je vrienden worden gewaardeerd, komen dan hoger in de zoekresultaten. Bij Google levert zoeken op “leuk restaurantje utrecht” dezelfde resultaten op als wanneer je moeder of je buurman hierop zou zoeken. Met de techniek die Facebook nu ontwikkelt, is voor iedereen een andere volgorde denkbaar. Want iedereen heeft andere vrienden en andere voorkeuren.
Facebook opent nu de aanval op Google met een nieuwe manier van zoeken en gevonden worden. Met “Like” buttons kunnen mensen aangeven welke website of webpagina ze “leuk” vinden. Hiermee tippen ze enerzijds hun vrienden, zoals StumbleUpon dit ook doet, maar wordt deze informatie ook gebruikt om zoekresultaten in Facebook te rangschikken. Websites die door veel van je vrienden worden gewaardeerd, komen dan hoger in de zoekresultaten. Bij Google levert zoeken op “leuk restaurantje utrecht” dezelfde resultaten op als wanneer je moeder of je buurman hierop zou zoeken. Met de techniek die Facebook nu ontwikkelt, is voor iedereen een andere volgorde denkbaar. Want iedereen heeft andere vrienden en andere voorkeuren.
(EDIT:) Uiteraard zit ook Google niet stil en pogen ook zij een graantje in de Social Search mee te pikken. Platforms als Google Buzz, initiatieven als Personalized Search maar ook verschillende social networks die Google start of koopt als Orkut, Jaiku of Google.me waarover meer en meer geschreven wordt.
Websites eigenaren opgelet: Maak websites Likebaar
Websites eigenaren opgelet: Maak websites Likebaar
![]() Facebook biedt webbouwers verschillende mogelijkheden om hun websites geschikt en vindbaar, of beter: Likebaar, te maken voor Facebook. Met Facebook Like Buttons maar bijvoorbeeld ook middels nieuwe soorten meta-tags (stukjes broncode speciaal gericht op de servers van Facebook). Naast een mooi ogende, overzichtelijke en zoekmachine-vriendelijke website begint social media nu ook aan de achterkant van websites belangrijk te worden. Want na Facebook, zullen ongetwijfeld ook andere sociale netwerken met dergelijke initiatieven komen gevolgd door nieuwe innovaties als Flattr waar men geld kan doneren voor content die je waardeert. Flattr leert op die manier eveneens welke informatie op Internet waardevol dan wel waardevoller is en wat jij wel en niet interessant vindt. Wat volgt er nog meer? Ongetwijfeld zal Google niet stil blijven zitten en door meer te leren van jou als persoon en alle social media om je heen.
Facebook biedt webbouwers verschillende mogelijkheden om hun websites geschikt en vindbaar, of beter: Likebaar, te maken voor Facebook. Met Facebook Like Buttons maar bijvoorbeeld ook middels nieuwe soorten meta-tags (stukjes broncode speciaal gericht op de servers van Facebook). Naast een mooi ogende, overzichtelijke en zoekmachine-vriendelijke website begint social media nu ook aan de achterkant van websites belangrijk te worden. Want na Facebook, zullen ongetwijfeld ook andere sociale netwerken met dergelijke initiatieven komen gevolgd door nieuwe innovaties als Flattr waar men geld kan doneren voor content die je waardeert. Flattr leert op die manier eveneens welke informatie op Internet waardevol dan wel waardevoller is en wat jij wel en niet interessant vindt. Wat volgt er nog meer? Ongetwijfeld zal Google niet stil blijven zitten en door meer te leren van jou als persoon en alle social media om je heen.
(Edit:) Belang van SEO verdwenen?
Voor de volledigheid, in navolging van verschillende reacties op dit artikel van professionals die hun geld verdienen met SEO, moge het duidelijk zijn dat dit artikel niet het einde aankondigt van SEO of Search. Sterker nog, social media heeft ervoor gezorgd dat ook zoekmachines als Google genoodzaakt zijn hun algoritmes bij te stellen en zoekresultaten nog beter afstemmen op de persoon. Zoekmachines zijn (en blijven) van groot belang. Dat zal niemand tegenspreken, zo ook dit artikel. Juist nu ook zoekmachines het belang van social media hebben ingezien en deze actief opnemen in hun zoekresultaten. Voor websitebouwers is dit alles alleen maar goed nieuws. Je kunt websites naast zoekmachine vriendelijk nu ook nog “social media vriendelijk” maken. Zo kan je traffic genereren uit social media en social networks, maar kunnen ze elkaar ook nog eens versterken. Nu zoekmachines social media gebruiken om de zoekresultaten af te stemmen, is het belangrijk om als website bouwer en eigenaar niet alleen maar aan SEO te werken, maar ook te zorgen dat je website Likebaar is.
Eens proberen? Klik dan hieronder op de Facebook Like button.
(Geschreven door Godfried van Loo, Creative Director & Founder Yocter b.v.)
loading...
loading...
Twitter keert developers de rug toe

Verschillende nieuwsberichten, uiteenlopende gevolgen en allerlei reacties omtrent Twitter deze week. Zo bracht Twitter advertenties naar de berichtenstroom genaamd ‘promoted tweets‘. Maar er is ook meer opvallend nieuws. Twitter gaat zich nu ook bezighouden met applicaties waarmee je Twitter kunt bereiken vanaf bijvoorbeeld een mobiele telefoon. Voorheen bemoeide Twitter zich niet veel met deze kant van de dienst om zo de vele duizenden ontwikkelaars niet te dwarsbomen die speciaal voor de dienst allerlei applicaties hebben ontwikkeld. Keert Twitter hen nu de rug toe?
Twitter = meer dan Twitter alleen
 Twitter is een online dienst met uiteraard eigen servers, personeel en een niet onaardig bedrijfspand, maar Twitter behelst veel meer dan dat. Duizenden zogenoemde Twitter Clients (programma’s) maken het mogelijk voor de miljoenen gebruikers om de dienst ook vanuit andere platforms dan hun internet browser te bereiken. Denk aan desktop programma’s op een computer, applicaties op mobiele telefoons maar ook zijn er Twitter Clients ontwikkeld om koppelingen met andere netwerken te realiseren. Zoals met Facebook, Hyves of LinkedIn.
Twitter is een online dienst met uiteraard eigen servers, personeel en een niet onaardig bedrijfspand, maar Twitter behelst veel meer dan dat. Duizenden zogenoemde Twitter Clients (programma’s) maken het mogelijk voor de miljoenen gebruikers om de dienst ook vanuit andere platforms dan hun internet browser te bereiken. Denk aan desktop programma’s op een computer, applicaties op mobiele telefoons maar ook zijn er Twitter Clients ontwikkeld om koppelingen met andere netwerken te realiseren. Zoals met Facebook, Hyves of LinkedIn.
Deze applicaties hebben Twitter mede helpen groeien omdat zij de dienst beschikbaar en bruikbaar maken voor de miljoenen gebruikers die Twitter inmiddels hebben ontdekt. De ontwikkelaars concurreren dan ook vooral met elkaar. Zo zijn er meerdere Twitter Apps voor de iPhone en andere type smartphones en vele Twitter programma’s voor op desktop computers. Zowel voor Apple Mac, Windows als Linux computers. Het gaat hen vooral om marktaandeel. “Ik wil meer gebruikers dan de concurrent” en daarom worden deze, veelal gratis programma’s, continu verbeterd en bijgewerkt.
Twitter koopt en maakt nu ook zelf Twitter Clients
 Maar Twitter lijkt zich nu ook tussen de ontwikkelaars in te gaan staan en met hen te gaan concurreren. Zo brengt Twitter een “officiële Twitter App” voor de BlackBerry smartphone op de markt, een telefoon van het Canadese Research in Motion (RIM). Dit niet tot vreugde van de ontwikkelaars die, veelal in hun vrije tijd, al veel eerder Twitter Apps voor de Blackberry hebben gemaakt en bang zijn voor oneerlijke concurrentie. Zo schrijft Paul McDonald van ontwikkelaar voor BlackBerry Twitter App UberTwitter aan de LA Times:
Maar Twitter lijkt zich nu ook tussen de ontwikkelaars in te gaan staan en met hen te gaan concurreren. Zo brengt Twitter een “officiële Twitter App” voor de BlackBerry smartphone op de markt, een telefoon van het Canadese Research in Motion (RIM). Dit niet tot vreugde van de ontwikkelaars die, veelal in hun vrije tijd, al veel eerder Twitter Apps voor de Blackberry hebben gemaakt en bang zijn voor oneerlijke concurrentie. Zo schrijft Paul McDonald van ontwikkelaar voor BlackBerry Twitter App UberTwitter aan de LA Times:
“Twitter’s new BlackBerry application uses many private APIs on the RIM platform that third-party developers like myself have no access to. In some ways, I think Twitter has shot itself in the foot.”
En Kevin Cawley van Tiny Twitter:
“I suspect this does nothing but dissuade developers from building BlackBerry apps out of fear of RIM squashing their efforts,” Cawley said in an e-mail. “I think RIM should focus on making better phones and building better tools for developers.”
 Twitter laat het niet alleen bij de BlackBerry. Zo maakte het bedrijf een paar dagen later bekend dat het Tweetie heeft gekocht, een succesvolle Twitter App voor de iPhone, en deze zal hernoemen tot ‘Twitter for iPhone’. De maker van Tweetie zal bovendien in dienst komen bij Twitter en gaan mehelpen aan een applicatie voor de iPad van Apple.
Twitter laat het niet alleen bij de BlackBerry. Zo maakte het bedrijf een paar dagen later bekend dat het Tweetie heeft gekocht, een succesvolle Twitter App voor de iPhone, en deze zal hernoemen tot ‘Twitter for iPhone’. De maker van Tweetie zal bovendien in dienst komen bij Twitter en gaan mehelpen aan een applicatie voor de iPad van Apple.
Schot in de rug of terecht verzilveren?
Twitter heeft nooit aan de ontwikkelaars die applicaties voor Twitter maken beloofd dat het dit niet op een dag zelf zou gaan doen. Het is dan ook part of the game. Toch zullen ontwikkelaars nu wel voorzichtiger zijn en mogelijk niet meer al hun energie stoppen in een Twitter applicatie die mogelijk, zodra er een potentie is geld te verdienen, wordt gekopieerd door Twitter zelf.
Toch klagen niet alle ontwikkelaars. “Het is een logische stap die we wel zagen aankomen” aldus Tony Haile van Betaworks dat verschillende Twitter applicaties waaronder TweetDeck heeft gemaakt. “Het zou naïef zijn om de winstgevendheid van je bedrijf volledig te laten afhangen van een ander bedrijf waar je zelf geen controle over hebt.”
Stoppen met ontwikkelen voor Twitter?
![]() Zullen ontwikkelaars na deze stappen van Twitter hun tijd en energie nog wel in Twitter willen stoppen? Nu Twitter zelf een officiele Twitter Applicatie voor de iPad gaat maken, heeft het dan nog wel zin om als ontwikkelaar ditzelfde te gaan proberen en direct te concurreren met het bedrijf waar je afhankelijk van bent? Of gaan ontwikkelaars zoeken naar een plek waar de kans op beloning groter is? Zoals het open-source platform Status.net?
Zullen ontwikkelaars na deze stappen van Twitter hun tijd en energie nog wel in Twitter willen stoppen? Nu Twitter zelf een officiele Twitter Applicatie voor de iPad gaat maken, heeft het dan nog wel zin om als ontwikkelaar ditzelfde te gaan proberen en direct te concurreren met het bedrijf waar je afhankelijk van bent? Of gaan ontwikkelaars zoeken naar een plek waar de kans op beloning groter is? Zoals het open-source platform Status.net?
loading...
loading...
Nu ook meedenkende fietsroutes in Google maps
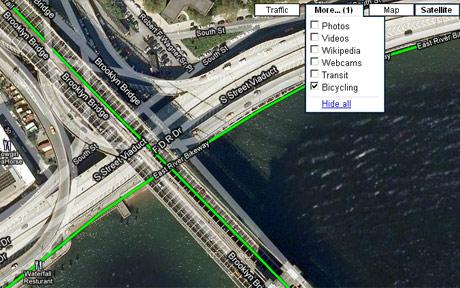
In fietsland Nederland kennen steeds meer mensen het volgende probleem… Je wilt van A naar B en laat Google berekenen hoe. Maar dan kan je kiezen uit een autoroute of wandelroute. Ga je omrijden of over de stoep? Google helpt want nu zijn er ook fietsroutes toegevoegd aan Google Maps!
Het heeft even geduurd voordat dit gebeurde, dit tot grote onvrede bij vele fietsers waarvan een stel zelfs een online petitie gestart waren. Meer dan 50.000 mensen hebben deze petitie ook daadwerkelijke getekend.
In Google Maps kunnen gebruikers nu het kopje “Bicycling” vinden bij de “Get Directions” drop-down box. Na het kiezen van deze optie kunnen fietsers twee adressen invoeren om zo de fietsroute te verkrijgen om op hun plaats van bestemming te kunnen komen. Net als bij de routekaartjes voor de auto krijg je ook bij je fietsroute meerdere opties te zien en een geschatte reistijd.
Jammer is dat de fietsroute-optie van Google Maps nu alleen nog maar van toepassing is op Amerika en meer specifiek op 150 Amerikaanse steden, waaronder (natuurlijk) Los Angeles, San Francisco en New York. De ‘fiets-tool’ is in staat meer dan 12.000 fietspaden uit te stippelen.
Google denkt met de fietser mee
Een van de fraaiste kenmerken van de Google Maps fiets-tool is de zogenaamde power-exertion calculation. Volgens Google houdt de tool namelijk rekening met de inspanning die de fietser moet leveren en de snelheid die een fietser heeft wanneer deze bergopwaarts moet fietsen. Met deze twee zaken rekening houdend, zal de tool een route uitstippelen die buitensporig of overbodige inspanning van de fietser vermijdt.
Google beweerd zelfs dat de tool ervoor zorgt dat de fietser weinig tot geen drukke kruispunten tegen komt en ook niet te veel hoeft te remmen.
De nieuwe Google Maps fiets-tool is in beta, wat wil zeggen dat het kan zijn dat het programma soms wat last heeft van bugs. In de aankomende maanden hoopt Google nog meer fietsroutes toe te voegen. Wachten is op het moment dat ook de Nederlandse fietspaden in kaart worden gebracht. Wat bij een fietsenland als dat van ons, toch niet te lang zou moeten duren.
loading...
loading...
Google zelf niet zo goed in zoekmachine optimalisatie (SEO)

Google heeft vorige week een rapport vrijgegeven waarin een analyse staat van hoe Google haar productpagina’s optimaliseert voor zoekmachines, inclusief haar eigen zoekmachine. De resultaten van deze analyse zijn echter niet zo rooskleurig.
In het zogenaamde SEO Report Card, samengesteld door drie Google-medewerkers, kreeg het bedrijf slechts één “uitstekend” voor de vele criteria waaraan het zou moeten voldoen. Daarnaast waren er drie “voldoendes” te bespeuren en maarliefst acht keer was “verbetering wenselijk”. Het rapport bevat alles tezamen een analyse van de hoofpagina’s van 100 Google-producten.
De resultaten van de SEO Report Card begonnen vorige maand al te circuleren binnen de kantoren van Google. Een flink aantal teams hebben ook al actie ondernomen (of zijn dit van plan) naar aanleiding van de niet zo positieve resultaten.
SEO, wat staat voor Search Engine Optimization, is in de laatste tien jaar uitgegroeid tot een hot item, aangezien internetgebruikers steeds meer zijn gaan vertrouwen op zoekmachines als Google, Yahoo en Bing bij het vinden van producten e.d.. Het is dan ook lichtelijk gênant te noemen dat het bedrijf dat zich de grootste en bekendste zoekmachine van de wereld mag noemen, zelf niet in staat is om haar eigen pagina’s goed te laten scoren.
loading...
loading...
Google Buzz: een nieuw social media platform
Op 8 februari lanceerde Google een nieuwe dienst onder de naam Google Buzz. Wat is dit voor dienst? Een social network? Een concurrent van Twitter? Ja en nee. Google Buzz is eerder een schilletje rond het social media platform waar Google al tijden mee bezig is.
 Allereerst de vergelijking met Twitter. Twitter is een dienst waar je met korte berichten van 140 tekens elkaar op de hoogte kunt houden. In deze berichten kan je eventueel verwijzen naar een foto of video, elders op het internet. Als ik op dit moment een foto wil delen met de rest van de wereld via een microblog dienst als Twitter, zal ik deze foto elders op het Internet moeten opslaan, zoals Twitpic. Iemand die de foto wil zien, zal de link naar mijn foto (bij Twitpic) moeten volgen en dus bij een andere dienst uitkomen. Zo deel ik niet zozeer een foto, maar een link naar deze foto.
Allereerst de vergelijking met Twitter. Twitter is een dienst waar je met korte berichten van 140 tekens elkaar op de hoogte kunt houden. In deze berichten kan je eventueel verwijzen naar een foto of video, elders op het internet. Als ik op dit moment een foto wil delen met de rest van de wereld via een microblog dienst als Twitter, zal ik deze foto elders op het Internet moeten opslaan, zoals Twitpic. Iemand die de foto wil zien, zal de link naar mijn foto (bij Twitpic) moeten volgen en dus bij een andere dienst uitkomen. Zo deel ik niet zozeer een foto, maar een link naar deze foto.
Google & social media
 Google is al met verschillende diensten een actieve speler in de wereld van social media. Google Buzz is dan ook eigenlijk niets nieuws. In 2007 kocht Google al Jaiku, een microblog dienst als Twitter, maar Google Buzz is veel meer dan kleine update berichtjes. Google Buzz is eerder een vorm van online sharing tool waarmee het vooral in de buurt komt van Google Wave. Of je nu tekst, een foto of video wilt delen… Doe dit vanuit een Google dienst naar keuze en de ander kan deze informatie eveneens openen in de interface waar hij of zij zich op dat moment bevindt.
Google is al met verschillende diensten een actieve speler in de wereld van social media. Google Buzz is dan ook eigenlijk niets nieuws. In 2007 kocht Google al Jaiku, een microblog dienst als Twitter, maar Google Buzz is veel meer dan kleine update berichtjes. Google Buzz is eerder een vorm van online sharing tool waarmee het vooral in de buurt komt van Google Wave. Of je nu tekst, een foto of video wilt delen… Doe dit vanuit een Google dienst naar keuze en de ander kan deze informatie eveneens openen in de interface waar hij of zij zich op dat moment bevindt.
Google Buzz is daarmee een dienst waarmee je andere mensen up-to-date kunt houden over wat je aan het doen bent en wat je beleeft zonder dat je daarvoor heen en weer wordt geslingerd van de ene naar de andere website. Zo kom je straks Google Buzz tegen in Gmail en Google Maps en kan je ook foto’s in Flickr of Picasa (eveneens van Google) eenvoudig delen maar ook openen, in bijvoorbeeld Gmail. Het is dan ook niet, zoals de eerste berichten over Google Buzz doen vermoeden, een social network voor Gmail. Welnee. Google kiest bewust voor een eerste implementatie in Gmail door de 170+ miljoen gebruikers dat de dienst gebruikt. Een aardig begin voor een potentiele doelgroep natuurlijk. Google Buzz zal echter langzaam overal worden geïntegreerd in andere Google diensten en met de API kunnen ontwikkelaars vervolgens Google Buzz en de informatie die daar wordt gedeeld, ook buiten het Google netwerk brengen.
Google Buzz <=> NS
 Google Buzz is dan ook meer een social media platform. Vergelijk het met de Nederlandse Spoorwegen:
Google Buzz is dan ook meer een social media platform. Vergelijk het met de Nederlandse Spoorwegen:
- De reizigers = social media (informatie die mensen willen delen)
- De stations = verschillende diensten waar informatie kan ‘opstappen’ en uitstappen (Gmail, Picasa, Google Maps, openSocial diensten,…)
- De treinen = Google netwerk en alle via API’s aangehaakte diensten
- Het spoor = het internet
Zo kan je straks informatie via Google Buzz verspreiden en ontvangen over en op allerlei andere plekken. Zo verspreid je of ontvang je social media met Gmail maar net zo goed via openSocial gadgets (bekend van iGoogle en diensten die openSocial ondersteunen als Hyves of LinkedIn) en via de API koppelingen die mogelijk zijn, kan dat dus ook via Twitter en zelfs op je eigen website of blog.
Google Buzz is daarom geen social network… maar een social media platform dat social media nog socialer maakt en het gemakkelijker is om deze informatie te verspreiden en te ontvangen.
loading...
loading...